Pandas Read Missing Values in Columns Whitespace
Missing Data can occur when no data is provided for one or more than items or for a whole unit. Missing Data is a very large problem in a real-life scenarios. Missing Data tin too refer to every bit NA(Not Bachelor) values in pandas. In DataFrame sometimes many datasets only arrive with missing data, either because it exists and was non nerveless or information technology never existed. For Example, Suppose dissimilar users being surveyed may choose not to share their income, some users may choose not to share the address in this fashion many datasets went missing.

In Pandas missing data is represented by ii value:
- None: None is a Python singleton object that is often used for missing data in Python code.
- NaN : NaN (an acronym for Not a Number), is a special floating-point value recognized by all systems that apply the standard IEEE floating-point representation
Pandas treat None and NaN equally essentially interchangeable for indicating missing or null values. To facilitate this convention, there are several useful functions for detecting, removing, and replacing zero values in Pandas DataFrame :
- isnull()
- notnull()
- dropna()
- fillna()
- replace()
- interpolate()
In this commodity we are using CSV file, to download the CSV file used, Click Here.
Checking for missing values using isnull() and notnull()
In order to check missing values in Pandas DataFrame, nosotros use a function isnull() and notnull(). Both function aid in checking whether a value is NaN or not. These function can as well be used in Pandas Series in order to find null values in a series.
Checking for missing values using isnull()
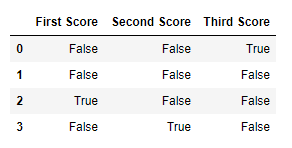
In order to cheque nil values in Pandas DataFrame, we apply isnull() function this function return dataframe of Boolean values which are True for NaN values.
Code #i:
import pandas as pd
import numpy equally np
dict = { 'First Score' :[ 100 , 90 , np.nan, 95 ],
'2d Score' : [ 30 , 45 , 56 , np.nan],
'3rd Score' :[np.nan, xl , lxxx , 98 ]}
df = pd.DataFrame( dict )
df.isnull()
Output:
Code #2:
import pandas as pd
information = pd.read_csv( "employees.csv" )
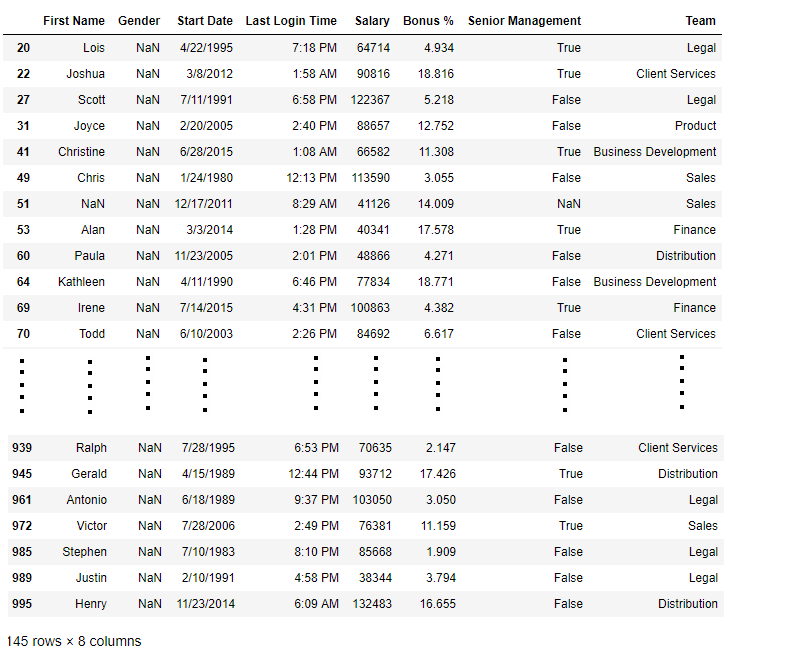
bool_series = pd.isnull(data[ "Gender" ])
data[bool_series]
Output:
As shown in the output epitome, only the rows having Gender = Zero are displayed.
Checking for missing values using notnull()
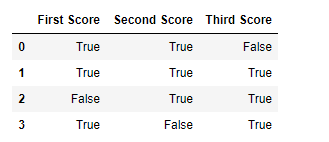
In order to check cypher values in Pandas Dataframe, we use notnull() function this function return dataframe of Boolean values which are False for NaN values.
Code #3:
import pandas as pd
import numpy as np
dict = { 'Starting time Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ 30 , 45 , 56 , np.nan],
'Tertiary Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.notnull()
Output:
Code #four:
import pandas as pd
data = pd.read_csv( "employees.csv" )
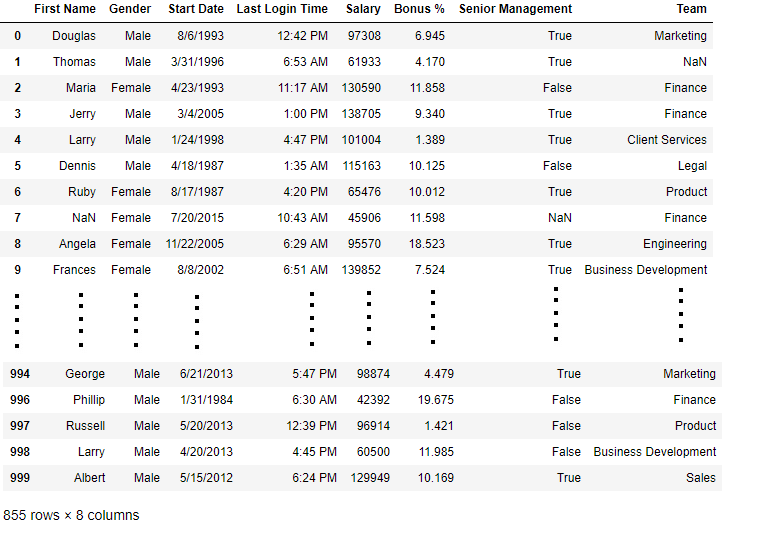
bool_series = pd.notnull(data[ "Gender" ])
data[bool_series]
Output:
Equally shown in the output epitome, merely the rows having Gender = Not Null are displayed.
Filling missing values using fillna(), supervene upon() and interpolate()
In order to fill null values in a datasets, we use fillna(), supplant() and interpolate() role these office supersede NaN values with some value of their own. All these function aid in filling a null values in datasets of a DataFrame. Interpolate() office is basically used to fill NA values in the dataframe but it uses various interpolation technique to fill the missing values rather than difficult-coding the value.
Code #1: Filling cipher values with a single value
import pandas equally pd
import numpy as np
dict = { 'Showtime Score' :[ 100 , 90 , np.nan, 95 ],
'2d Score' : [ 30 , 45 , 56 , np.nan],
'Third Score' :[np.nan, 40 , fourscore , 98 ]}
df = pd.DataFrame( dict )
df.fillna( 0 )
Output:
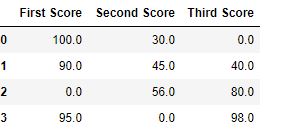
Lawmaking #two: Filling cypher values with the previous ones
import pandas as pd
import numpy every bit np
dict = { 'Showtime Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ thirty , 45 , 56 , np.nan],
'Third Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.fillna(method = 'pad' )
Output:
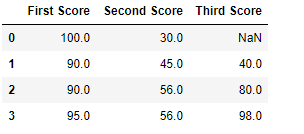
Lawmaking #3: Filling null value with the adjacent ones
import pandas every bit pd
import numpy as np
dict = { 'First Score' :[ 100 , xc , np.nan, 95 ],
'2d Score' : [ 30 , 45 , 56 , np.nan],
'3rd Score' :[np.nan, 40 , 80 , 98 ]}
df = pd.DataFrame( dict )
df.fillna(method = 'bfill' )
Output:
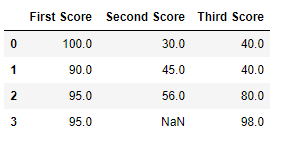
Lawmaking #4: Filling null values in CSV File
import pandas as pd
data = pd.read_csv( "employees.csv" )
data[ x : 25 ]
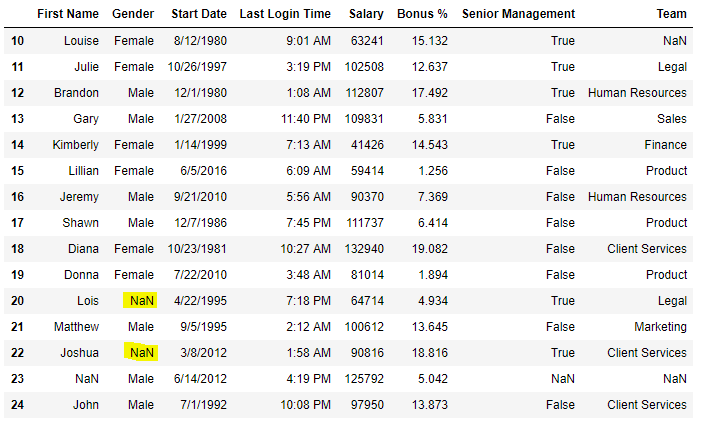
Now we are going to make full all the null values in Gender column with "No Gender"
import pandas every bit pd
data = pd.read_csv( "employees.csv" )
data[ "Gender" ].fillna( "No Gender" , inplace = True )
data
Output:
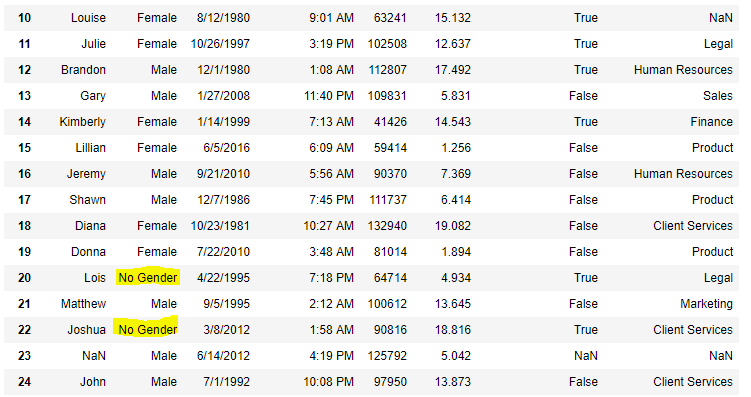
Lawmaking #5: Filling a cypher values using supersede() method
import pandas equally pd
data = pd.read_csv( "employees.csv" )
data[ 10 : 25 ]
Output:
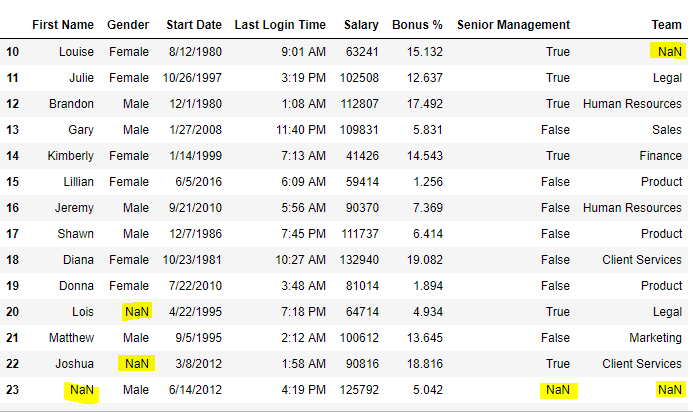
Now we are going to replace the all Nan value in the information frame with -99 value.
import pandas equally pd
data = pd.read_csv( "employees.csv" )
data.replace(to_replace = np.nan, value = - 99 )
Output:
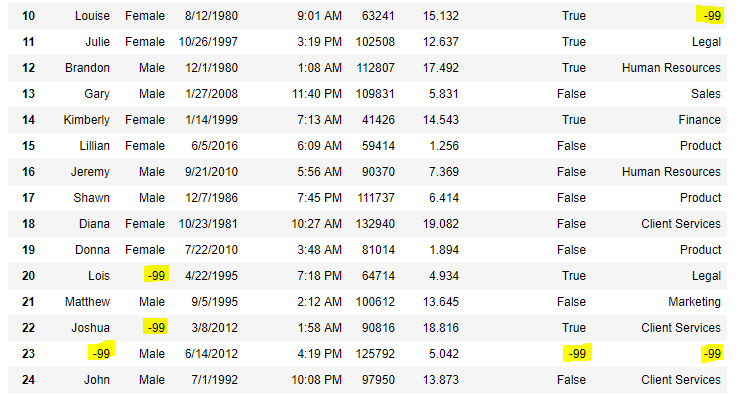
Lawmaking #6: Using interpolate() function to fill the missing values using linear method.
import pandas as pd
df = pd.DataFrame({ "A" :[ 12 , 4 , 5 , None , 1 ],
"B" :[ None , ii , 54 , 3 , None ],
"C" :[ 20 , xvi , None , three , 8 ],
"D" :[ xiv , three , None , None , half-dozen ]})
df
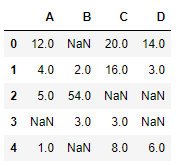
Permit'south interpolate the missing values using Linear method. Note that Linear method ignore the index and treat the values as equally spaced.
df.interpolate(method = 'linear' , limit_direction = 'frontwards' )
Output:
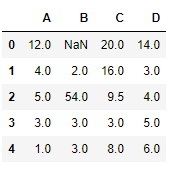
Equally nosotros can come across the output, values in the first row could not get filled as the direction of filling of values is forward and there is no previous value which could have been used in interpolation.
Dropping missing values using dropna()
In order to drop a zip values from a dataframe, we used dropna() function this function drop Rows/Columns of datasets with Nothing values in different means.
Code #1: Dropping rows with at least 1 null value.
import pandas as pd
import numpy equally np
dict = { 'First Score' :[ 100 , 90 , np.nan, 95 ],
'2d Score' : [ 30 , np.nan, 45 , 56 ],
'Tertiary Score' :[ 52 , 40 , 80 , 98 ],
'4th Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df
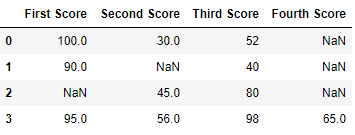
Now we drop rows with at to the lowest degree one Nan value (Zilch value)
import pandas as pd
import numpy as np
dict = { 'Kickoff Score' :[ 100 , 90 , np.nan, 95 ],
'Second Score' : [ thirty , np.nan, 45 , 56 ],
'Third Score' :[ 52 , 40 , 80 , 98 ],
'Fourth Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df.dropna()
Output:

Code #two: Dropping rows if all values in that row are missing.
import pandas as pd
import numpy as np
dict = { 'First Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Tertiary Score' :[ 52 , np.nan, eighty , 98 ],
'Fourth Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df
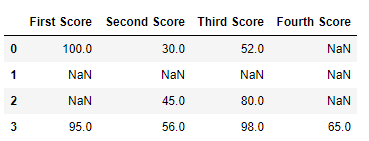
At present we drop a rows whose all data is missing or contain nix values(NaN)
import pandas as pd
import numpy as np
dict = { 'Showtime Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, 80 , 98 ],
'Fourth Score' :[np.nan, np.nan, np.nan, 65 ]}
df = pd.DataFrame( dict )
df.dropna(how = 'all' )
Output:
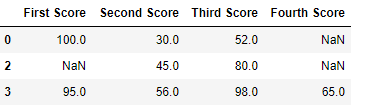
Code #three: Dropping columns with at to the lowest degree 1 null value.
import pandas as pd
import numpy as np
dict = { 'Showtime Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, eighty , 98 ],
'Fourth Score' :[ sixty , 67 , 68 , 65 ]}
df = pd.DataFrame( dict )
df
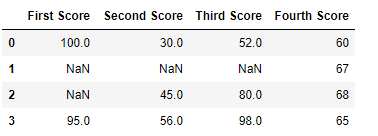
Now nosotros drop a columns which have at least i missing values
import pandas as pd
import numpy as np
dict = { 'Starting time Score' :[ 100 , np.nan, np.nan, 95 ],
'Second Score' : [ 30 , np.nan, 45 , 56 ],
'Third Score' :[ 52 , np.nan, lxxx , 98 ],
'4th Score' :[ sixty , 67 , 68 , 65 ]}
df = pd.DataFrame( dict )
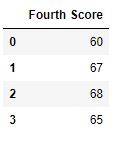
df.dropna(axis = i )
Output :
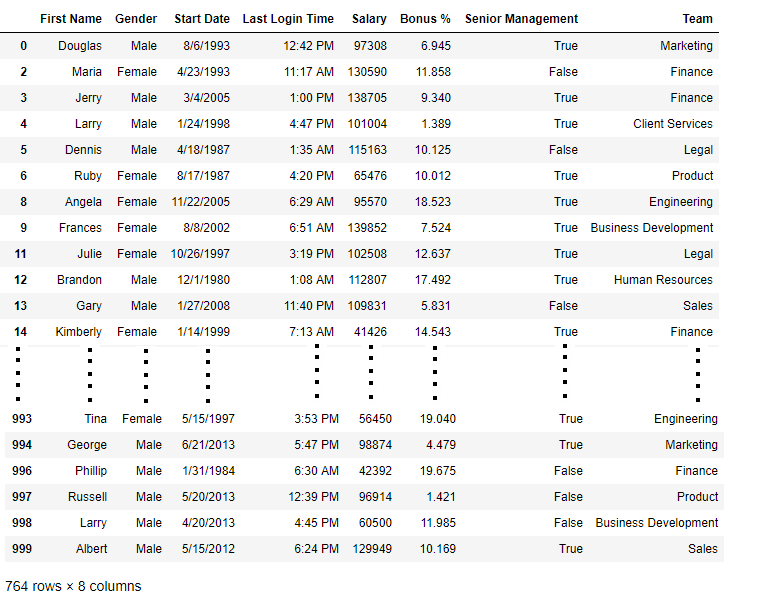
Lawmaking #4: Dropping Rows with at least 1 null value in CSV file
import pandas as pd
data = pd.read_csv( "employees.csv" )
new_data = data.dropna(axis = 0 , how = 'any' )
new_data
Output:
At present nosotros compare sizes of information frames so that we can come to know how many rows had at to the lowest degree ane Null value
print ( "Erstwhile data frame length:" , len (data))
impress ( "New data frame length:" , len (new_data))
print ( "Number of rows with at least one NA value: " , ( len (data) - len (new_data)))
Output :
Old data frame length: 1000 New data frame length: 764 Number of rows with at least 1 NA value: 236
Since the divergence is 236, there were 236 rows which had at least one Null value in whatsoever cavalcade.
Source: https://www.geeksforgeeks.org/working-with-missing-data-in-pandas/
0 Response to "Pandas Read Missing Values in Columns Whitespace"
Post a Comment